Scan Scope
The Scan Scope allows you to define which parts of the target web application should be crawled. This in turn, dictates what will be scanned; because unless a page, parameter, or any other object is first crawled, it will not be scanned.
This topic explains how to:
- Configure the scan scope
- Define the URL in the scan scope
- Configure the path in the scan scope
- Filter URLs in the scan scope
- Scan or exclude a subdirectory on the target website
Sometimes, you need to limit the scope of the scan. For example, if you want to scan a web application that uses data from external sources, you can configure the scanner to follow and scan the external sources (or not).
NOTE: By default, Invicti scanners do not follow and scan data from external sources. |

Another typical scenario is when you want to scan a web application that is installed in a subfolder, or only one section of a web application. For example, if the web application you want to scan is installed at http://www.example.com/app1 and you do not want the scanner to scan anything else from the http://www.example.com domain, you can configure the Scan Scope to restrict the scan to that subfolder.
Defining the URL in the Scan Scope
A website is defined in Invicti as a Fully Qualified Domain Name (FQDN). An FQDN is the complete domain name for a specific target and consists of two parts: the hostname and the domain name.
A domain is a group of computers or IP addresses accessed and administered within the same network. Each domain has a name, such as example.com. In the online environment, a domain name is your website. Under the domain, you can create as many hosts as you want. The web server hosts the documents.
Previously, in order to visit a website with the name 'example.com', visitors had to type the 'www' hostname as a prefix (though there was no technical obligation). Many domains still have a 'www' hostname by default. The FQDN is therefore 'www.example.com'.
A domain name without the 'www' part is referred to as "the origin". 'www' stands for the general subdomain of your website. Today, both the origin and the www host are mostly redirected to the same IP address and considered to be the same FQDN. Any other hostname, except www, changes the FQDN. For example, www.example.com and api.example.com would count as two different FQDNs.
This diagram explains the structure of a URL.
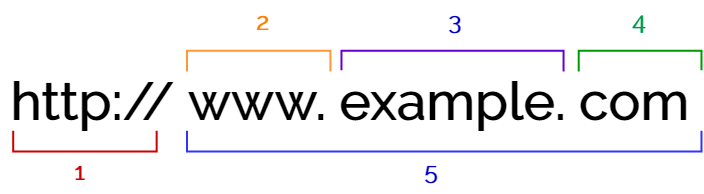
- The protocol
- The host or hostname
- Domain
- Top-Level-Domain (TLD)
- Fully Qualified Domain Name (FQDN)
These examples are all considered to be one website, as they share the same FQDN.
- http://example.com
- https://example.com
- http://www.example.com
- http://www.example.com/test
Subdomains and ports are considered to be different websites even though they share the same FQDN.
- http://api.example.com
- http://test.example.com
- http://example.com:81
Configuring the URL Path
There are three options available:
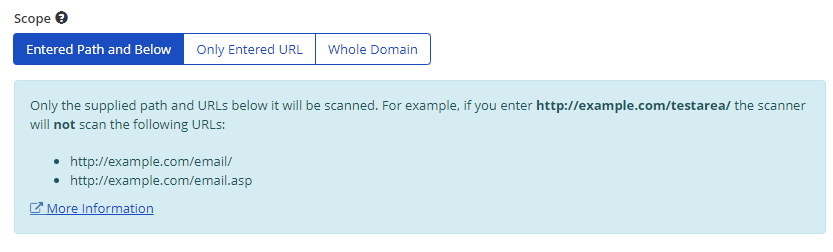
Entered Path and Below
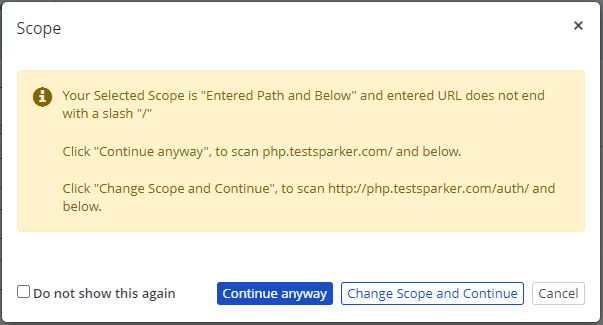
When you select Entered Path and Below, Invicti will only crawl and attack the target path and all the URLs under that path. If you enter the URL https://example.com/testfolder/ the following URLs will be crawled:
- https://example.com/testfolder/test.php
- https://example.com/testfolder/test/modify.php
- https://example.com/testfolder/test/
The following URLs will not be crawled:
- http://example.com/test.php; this URL is not under the given target.
- http://test.example.com; this URL is of a different domain.
NOTE: If you do not enter a trailing slash in the target URL, Invicti assumes that the target URL ends with the last available slash in the URL and will alert you with the notification as illustrated. |
Only Entered URL
When you select Only Entered URL, Invicti will only crawl the target URL and no external links are followed. This function is useful if you want to only test one page and all the parameters in that page without testing the whole web application. If you enter https://example.com/testfolder/test.php the following URLs will be crawled:
- https://example.com/testfolder/test.php
- https://example.com/testfolder/test.php?id=1
The following URLs will not be crawled:
- https://example.com/testfolder/register.php; the URL path is different than the one in the target URL
- http://example.com/testfolder/test.php; the protocol is different. Target URL was HTTPS.
NOTE: If you enter http://example.com/test, URLs such as http://example.com/testx will also be crawled. In this case the second URL is scanned because it contains the target URL. |
Whole Domain
When you select Whole Domain, Invicti will start crawling and scanning the target URL and all URLs beginning with the same hostname, regardless of the scheme and port number. Therefore if you enter https://example.com/testfolder/test.php the following URLs will be tested:
- https://example.com/index.php
- http://example.com/register/
- https://example.com/testfolder/test.php
- http://example.com/testfolder/test/test.php?id=1
Configuring the Scan Scope
You can configure the scan scope in Invicti Standard and Invicti Enterprise.
For further information, refer to the relevant sections of Creating a new Scan:
- Invicti Enterprise: Scan Scope section
- Invicti Standard: Scan Settings - Scope section
Scan Scope Fields
This table lists and describes the fields in the Scan Scope tab.
Field | Description |
Entered Path and Below | This tab enables you to specify which parts of the target website should be crawled and scanned. If, for example, you enter http://example.com/testarea/, the scanner will not scan the following URLs:
|
Only Entered URL | This tab enables you to scan only the supplied URL and the parameters on that page. If, for example, you enter http://example.com/test.asp, the scanner will only scan URLs that start with http://example.com/test.asp, and will not scan the following:
|
Whole Domain | This tab enables you to scan the entire domain, even if you only entered the URL of a page or a directory. If, for example, you enter http://example.com/test.asp, the scanner will start from the test.asp page and scan everything on the http://example.com domain. |
Do not differentiate HTTP and HTTPS protocols | When checked, the links will be accepted in the scope, even if the target URL protocol does not match. This option is only valid for Entered Path and Below, and Whole Domain settings. |
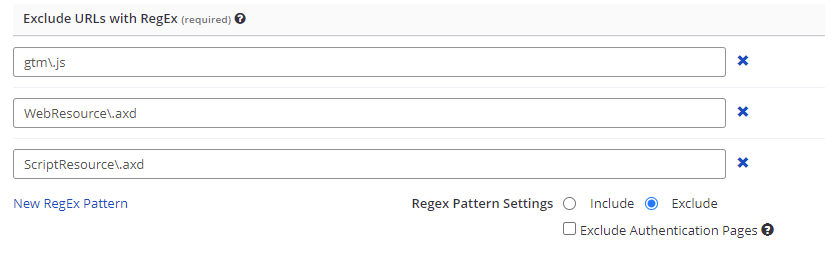
Exclude URLs with RegEx | In this section, list and configure the URLs you want included or excluded. |
Include/Exclude | If you choose Include, Invicti Enterprise will only test URLs that match any of the given regular expression. If you choose Exclude, Invicti Enterprise will not visit and test URLs that match any of the given regular expressions. |
Exclude Authentication Pages | When checked, Invicti will exclude authentication-related web pages – such as login and logout – from the scan scope to prevent logging out during the scan. When Form Authentication is enabled, this option is also enabled by default. |
New RegEx Pattern | This creates a new RegEx Pattern field. |
Disallowed HTTP Methods | Select HTTP methods to disallow. Invicti won’t make HTTP requests for the selected methods. |
Excluded Usage Trackers | Specify URL(s) or wildcard(s) to enable Invicti to exclude usage tracking requests from the scan. Including usage tracking requests in a scan may extend the scan duration. |
How to Configure the Scan Scope in Invicti Enterprise
- Log in to Invicti Enterprise.
- From the main menu, select Scans > New Scan.
- Select the Scope tab.
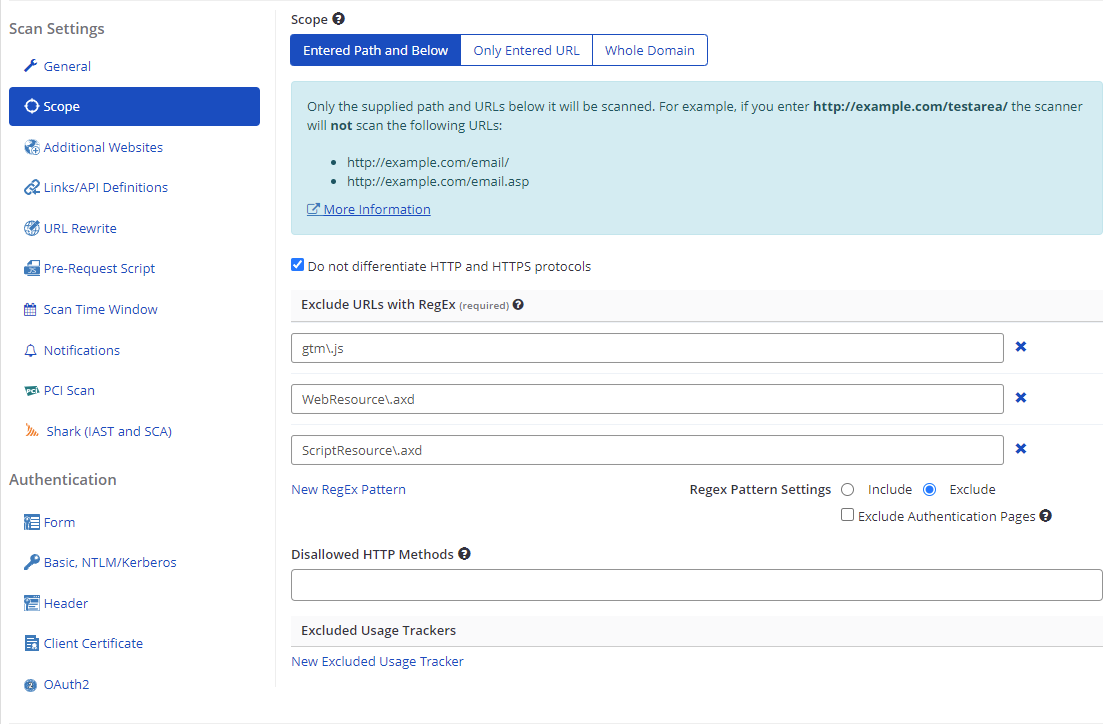
- In the Target URL field, enter a URL (refer to Defining the URL in the Scan Scope).
- Select one of the following tabs (refer to Configuring the URL Path):
- Entered Path and Below
- Only Entered URL
- Whole Domain
- Select Delete () next to any item, if required.
- Select New RegEx Pattern to create a new field, if required.
- Enable Include or Exclude, which will be applied to the configuration you have just entered (refer to Scanning Subdirectories).
- Enable the Exclude Authentication Pages, if required.

- Select Disallowed HTTP Methods from the drop-down, if required.
- In the Excluded Usage Trackers field, select New Excluded Usage Tracker to specify URL(s) or wildcard(s).
- Select Launch.
How to Configure the Scan Scope in Invicti Standard
- Open Invicti Standard.
- In the Home tab, select New. The Start a New Website or Web Service Scan dialog is displayed.
- From Start a New Website or Web Service Scan dialog, select the Scope tab.
- In the Target Website or Web Service URL field, enter the URL (refer to Defining the URL in the Scan Scope).
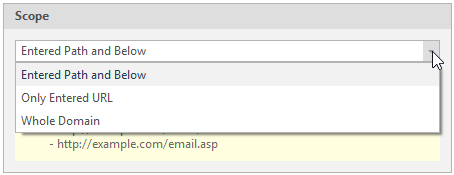
- In the Scope drop-down, select an option (refer to Configuring the URL Path):
- Entered Path and Below
- Only Entered URL
- Whole Domain
- Include or delete RegEx, as required.
- In Exclude URLs with RegEx, enable Include or Exclude (refer to Scanning Subdirectories) and select Exclude Authentication Pages if required.
- Select Disallowed HTTP Methods from the dropdown, if required.
- In the Excluded Usage Trackers field, specify URL(s) or wildcard(s).
- Complete the remaining Scan Options and Authentication, as required (refer to Invicti Standard Scan Option Fields and Configuring Form Authentication in Invicti Standard).
- Select Start Scan.
Filtering URLs in the Scan Scope
It is possible to exclude or include URLs in the Scan Scope using regular expressions. By default, the Exclude option is selected and there are three predefined regular expressions. There is a further option that is used to exclude URLs that might end an authenticated session. When Invicti finds a URL that matches one of these regular expressions, it will not crawl or scan the page to prevent session logout, if configured to do so.
NOTE: When you use the Include option, the Invicti scanners will ONLY crawl and scan the URLs that match those regular expressions. |
How to Filter URLs in the Scan Scope in Invicti Enterprise
- Log in to Invicti Enterprise.
- From the main menu, select Scans > New Scan.
- Select the Scope tab.
- In New RegEx Pattern, enable Include or Exclude.

- Enable the Exclude Authentication Pages, if required.
- Select Launch.
How to Filter URLs in the Scan Scope in Invicti Standard
- Open Invicti Standard.
- From the Start a New Website or Web Service Scan dialog, in the Scan Setting menu, select Scope.
- In Exclude URLs with RegEx, enable Include or Exclude.
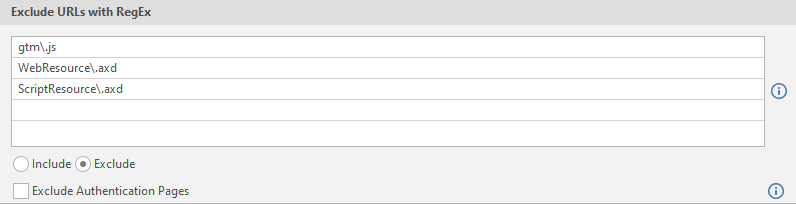
- Enable the Exclude Authentication Pages, if required.
- Select Start Scan.
Writing Regular Expressions to Include/Exclude URLs
You do not need to be knowledgeable about regular expressions to filter URLs. All you need to know is that there are a few special characters that when used in a regular expression and are not part of it you must escape with backslash. These characters are ()|.*+-?
So if the URL for which you want to write a regex contains one of those characters, just escape. Read the Wikipedia article on Regular Expressions for more information.
Example of How to Filter URLs with RegEx
In a typical logged in session is a link on all pages that allows the user to log out, such as:
<a href="session-end.php">Logout</a>
If Invicti crawls this link during the scan, it will end the session. To ensure the scanner scans all the pages, you need to exclude that URL from the scan. To do so we need to write a regular expression to match the URL session-end.php. Since it contains special characters (hyphen and dot) that need to be escaped the regular expression should be:
session\-end\.php
Notice the backslash being used to escape the - and the . characters. If on the other hand you want to make sure Invicti always crawls and scans such URLs, use the same regular expression and tick the option Include.
Scan Scope Exceptions
It is important to point out that there are some exceptions during which Invicti will ignore the Scan Scope configuration. These are highlighted below:
- During authentication: most of the time successful or failed login attempts are redirected to a page which can be out of scope. In this case, the scanner would still need to crawl the page to check whether or not the authentication succeeded. For this reason, Invicti does not check the Scan Scope configuration during authentication requests.
- The target URL to scan is never checked against the scope. Only the crawled pages crawled from the target URL are checked.
- The scanner will request JavaScript files that are located on external domains (common in a CDN setup) while performing JavaScript (DOM) Simulation (parsing) and DOM XSS attacks irrelevant of the Scan Scope configuration.
Scan Scope Examples
Here are two scan scope examples:
Scanning a subdirectory
In some cases, you may want to scan specific parts of your website. For example:
- You've created a new directory on your project and you want to scan only the pages in this directory.
- You've run an authenticated scan and the /login directory caused a problem during the scan. In this case, you need to exclude the /login directory, but this time the directory will not be scanned. You need to create another scan without authenticating it to scan the /login directory.
You should be aware that with these settings all pages under the subdirectory will be scanned.
Target website setup
- The web application URL is http://example.com
- You want to scan http://example.com/admin/
Scan scope configuration
- Scope: Entered Path and Below
- Target URL: http://example.com/admin/
- Include Regex (Optional): /admin
How to scan a subdirectory on the Target Website in Invicti Enterprise
- Log in to Invicti Enterprise.
- From the main menu, select Scans > New Scan.
- In the New Scan window, select the Scope tab.
- Enter the Target URL (e.g. http://example.com/admin/).
- Select Enter Path and Below.
- Check Do not differentiate HTTP and HTTPS protocols if required.
- Enable Include in New RegEx Pattern.
- Select New RegEx Pattern.
- Enter the subdirectory in the new field (e.g. ScriptResource\.axd).

- Check Exclude Authentication Pages if required.
- Select Launch.
How to scan a sub-category on the Target Website in Invicti Standard
- Open Invicti Standard.
- In the Home tab, click New.
- In Scan Settings, click the Scope tab.
- Enter the Target URL or Web Service URL (e.g. http://example.com/admin/).
- From the Scope drop-down, select Enter Path and Below.
- Check Do not differentiate HTTP and HTTPS protocols if required.
- In Exclude URLs with RegEx, enable Include.
- Enter the subdirectory in the new field (e.g. /admin).
- Check Exclude Authentication Pages if required.
- Select Start Scan.
Excluding a subdirectory
Target website setup
- The web application URL is http://example.com
- You want to exclude http://example.com/admin/
Scan scope configuration
- Scope: Entered Path and Below
- Target URL: http://example.com/
- Exclude Regex: /admin
How to exclude a subdirectory on the Target Website in Invicti Enterprise
- Log in to Invicti Enterprise.
- From the main menu, select Scans > New Scan.
- Select the Scope tab.
- Enter the Target URL (e.g. http://example.com/admin/).
- Select Enter Path and Below.
- Check Do not differentiate HTTP and HTTPS protocols if required.
- Enable Exclude in New RegEx Pattern.
- Select New RegEx Pattern. A new Include URLs with RegEx field is displayed.
- Enter the subdirectory in the new field (e.g. /admin).
- Check Exclude Authentication Pages if required.
- Select Launch.
How to exclude a subdirectory on the Target Website in Invicti Standard
- Open Invicti Standard.
- In the Home tab, select New.
- From the Start a New Website or Web Service Scan dialog, in Scan Settings, select the Scope tab.
- Enter the Target URL or Web Service URL (e.g. http://example.com/admin/).
- From the Scope drop-down, select Enter Path and Below.
- Check Do not differentiate HTTP and HTTPS protocols if required.
- In Exclude URLs with RegEx, enable Exclude.
- Enter the subdirectory in the new field (e.g. /admin).
- Check Exclude Authentication Pages if required.
- Select Start Scan.