Information disclosure vulnerabilities and attacks in web applications
Information disclosure issues in web applications can be used by attackers to obtain useful knowledge about the possible weaknesses of a web application, thus allowing them to craft a more effective hack attack.
Your Information will be kept private.
Your Information will be kept private.

Information disclosure happens when an application fails to properly protect sensitive and confidential information from exposure to users who are not normally supposed to have access to that data. While such issues are not exploitable in most cases, they are still considered web application security issues because they allow malicious hackers to gather valuable information that can be used later in the attack lifecycle. Armed with such data, attackers they can achieve much more than they could without it.
Different types of information disclosure issues
This article highlights a number of information disclosure issues in web applications along with common mistakes made by developers and webmasters that can lead to the disclosure of confidential and sensitive information. The list also includes examples of each information disclosure security issue and explains how to find such vulnerabilities.
Banner grabbing (active reconnaissance)
Banner grabbing or active reconnaissance is a type of attack during which the attackers send requests to the system they are attempting to attack in order to gather more information about it. If the system is not securely configured, it may leak information about itself, such as the server version, PHP/ASP.NET version, OpenSSH version, etc.
In most cases, banner grabbing does not involve the leakage of critical data but rather information that may aid the attacker during the exploitation phase of the attack. For example, if the target leaks the version of PHP running on the server and that version happens to be vulnerable to remote code execution (RCE) because it wasn’t updated, attackers may exploit the known vulnerability and take full control of the web application.
Here is an example of banner grabbing:
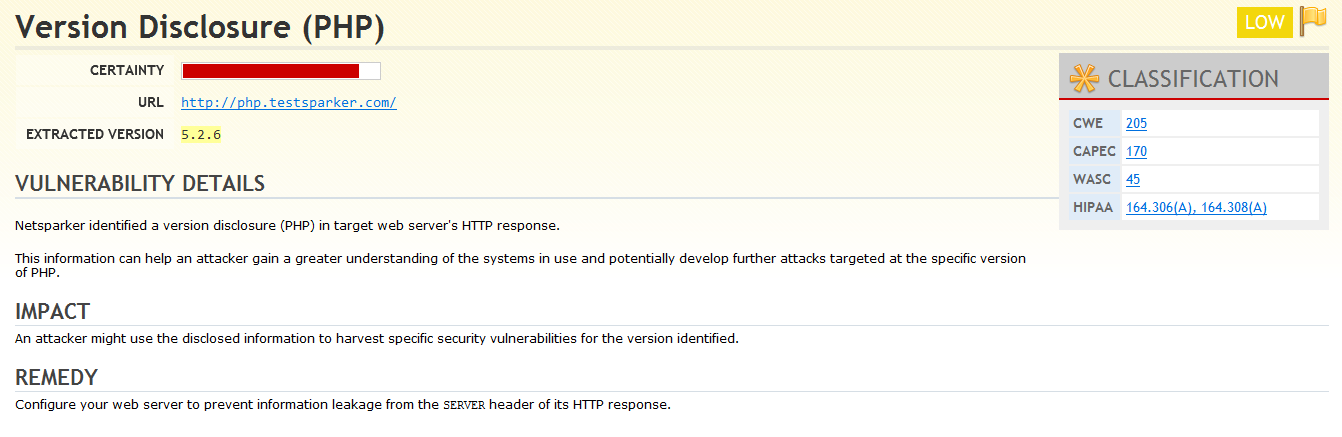
We can see that Netsparker identified an old version of PHP running on the target host. You can also use the HTTP Request / Response tab in Netsparker to see the HTTP response from the target service in raw format, in which the old version of PHP is highlighted as well.
Source code disclosure
Source code disclosure issues occur when the code of the backend environment of a web application is exposed to the public. Source code disclosure enables attackers to understand how the application behaves by simply reading the code and checking for logical flaws, or hardcoded username/password pairs, or API secret keys. The severity here depends on how much of the code is exposed, and how critical the leaked lines of code are for the security of the web application. In short, source code disclosure turns a black box testing process into more of a white box testing approach since attackers get access to the code.
Source code disclosure issues can occur in numerous ways, below are some of them:
Unprotected public code repositories
Many often host their source code in the cloud in order to improve collaborative development methods. Such repositories are sometimes not well protected and may allow attackers to access the hosted source code and information. Also, some companies which develop open source software use public repositories so that the public can contribute to the project. In this case the source code is already public, but it is not the first time the publicly available source code contained sensitive information.
Some source code repositories only allow users to see their content based on an authentication process. Such repositories are sometimes incorrectly configured, leaving their content accessible to anyone that for example has a particular email address or failing to restrict access to certain accounts that should have such levels of access.
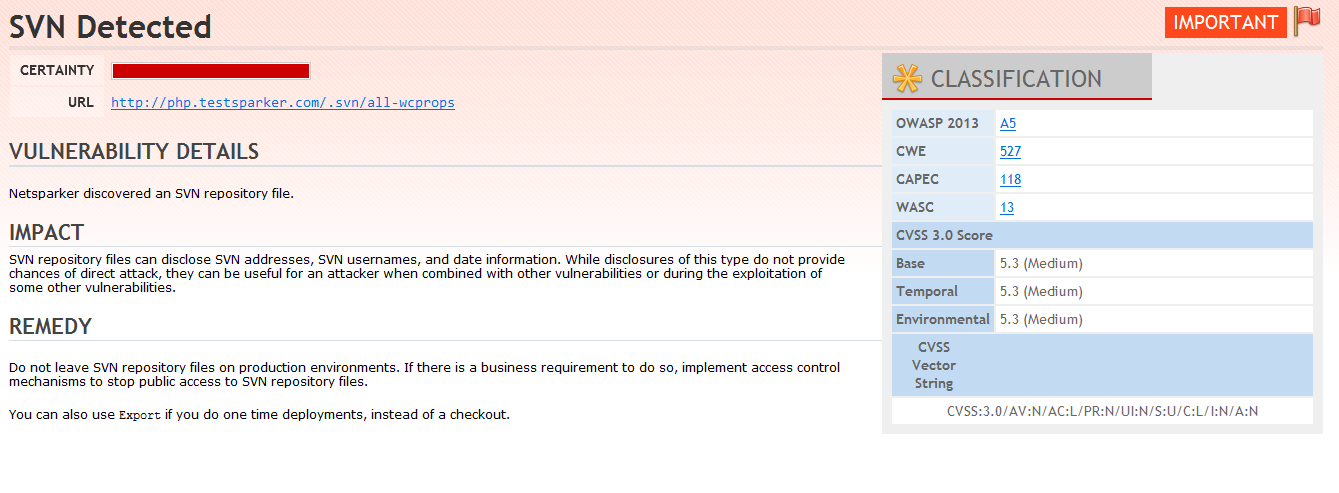
The Netsparker scanner has identified an SVN repository on the target website
Another example is when the public code has sensitive information hardcoded in it, such as user credentials or API secret keys. Attackers can easily use such information to sabotage these services or cause accessibility issues for legitimate users. Another piece of information that is typically disclosed during information disclosure are internal IP addresses, allowing attackers to identify and learn about the internal network topology. Such information can then be used to pivot into the network and attack multiple systems via a server-side request forgery (SSRF) attack for example.
Incorrect MIME types
Web browsers know how to parse the information they receive thanks to the Content-Type HTTP header that the web server sends in its HTTP responses. For example, in the screenshot below, we can see that the Content-Type header is set to text/html, so the browser parses the HTML and shows the output.
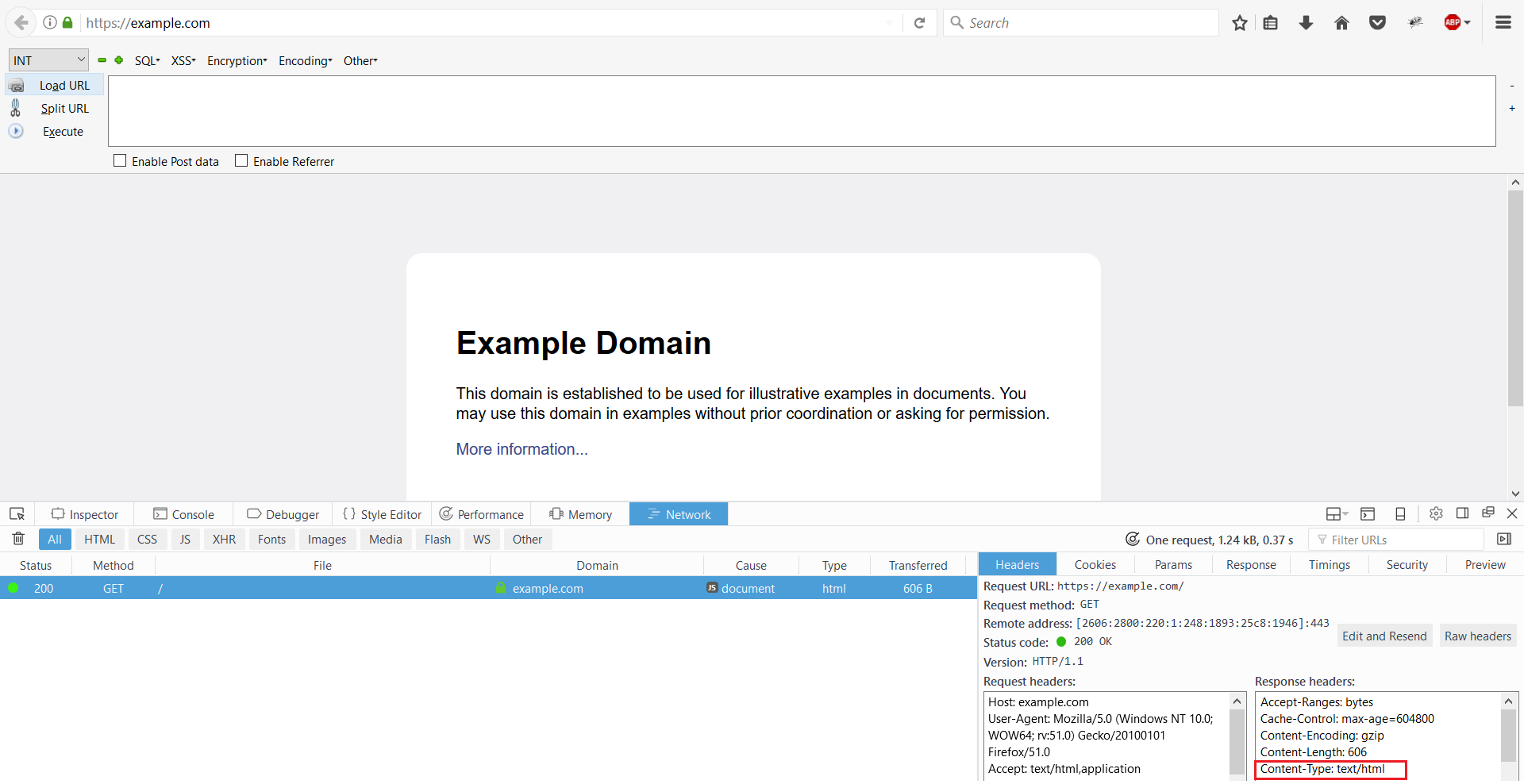
If the web server is misconfigured and (for example) sends the header Content-Type: text/plain instead of Content-Type: text/html when serving an HTML page, the code will be rendered as plain text in the browser, allowing the attacker to see the source code of the page.
Inappropriate handling of sensitive data
Another common mistake is hardcoding sensitive information such as username/password pairs, internal IP addresses in scripts, and comments in code and web pages. In most cases, such information is released on the production web application. The disclosure of such information can be devastating for web application security because all the attacker has to do is look for such information in the source of those web pages (i.e. by doing a right click on the page and then selecting View Page Source, not to be confused with the server-side application source code).
Netsparker will alert you if it finds possible sensitive information in the comments of the web application during a scan.
Filename and file path disclosure
In some circumstances, web applications can disclose filenames or paths, thus revealing information about the structure of the underlying system. This can happen due to incorrect handling of user input, exceptions at the backend, or inappropriate configuration of the web server. Sometimes such information can be found or identified in the responses of the web applications, error pages, debugging information etc.
A simple test an attacker can do to check if the web application discloses any file names or paths is to send a number of different requests that the target might handle differently. For example when sending the below request the web application returns a 403 (Forbidden) response:
https://www.example.com/%5C../%5C../%5C../%5C../%5C../%5C../etc/passwdBut when the attacker sends the following sequence, this gets a 404 (Not found) response:
https://www.example.com/%5C../%5C../%5C../%5C../%5C../%5C../etc/doesntexistSince for the first request the attacker got a 403 Forbidden error and for the second one a 404 Not Found, this reveals that in the first case, the requested file exists. The attacker can use such web application behavior both to discover how the server is structured and to verify whether a certain folder or file exists on the system.
Directory listing
Related to filename and path disclosure is directory listing in web servers. This functionality is provided by default on web servers. When there is no default web page to show, the web server returns a list of files and directories present on the website.
So if the default filename on an Apache web server is index.php and you have not uploaded a file called index.php to the root directory of your website, the server will show a directory listing of the root directory instead of parsing the PHP file, as shown in the below screenshot.
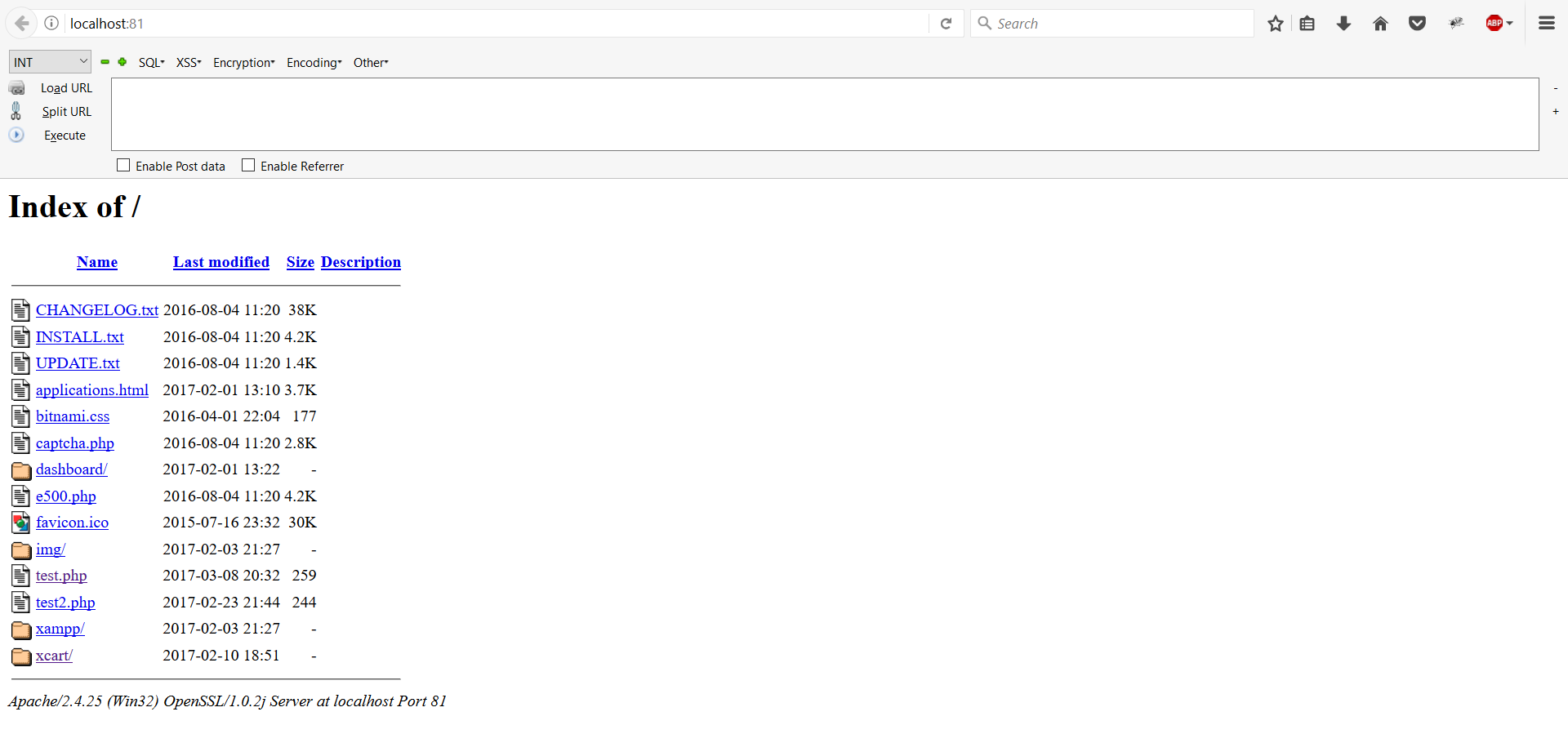
Leaving such functionality enabled in production environments is a bad practice and can lead to bigger security issues. Nowadays many are aware that such functionality should be disabled, so it is not common to see it.
Let’s assume, though, that after scanning the ports of a web server, the attacker found a default installation of the web server running on port 8081. Such “defaults” are typically overlooked by web server administrators, which also means they are much less secure. The installation may also have directory listing enabled, allowing the attacker to navigate through the directories and access source code, backup, and possibly database files of the web application.
Mitigating information disclosure vulnerabilities
Information disclosure security issues might seem trivial, but they are not. They allow malicious hackers to gain useful and confidential information about the target they want to attack just by performing basic testing or even just by looking for information in public pages. Netsparker reports information disclosure issues and under the Knowledge Base node it also reports any possible sensitive comments found in the code of the target website.
You should always address all such issues, especially when you consider that they are really easy to mitigate. Here are some guidelines for protecting your web applications against the most obvious information disclosure issues:
- Make sure that your web server does not send out response headers or background information that reveal technical details about the backend technology type, version or setup.
- Make sure that services running on the server’s open ports do not reveal information about their builds and versions.
- Always make sure that proper access controls and authorizations are in place in order to disallow access for attackers on all web servers, services and web applications.
- Make sure that all exceptions are well handled when the web application fails and no technical information is reported in the errors.
- Do not hardcode credentials, API keys, IP addresses, or any other sensitive information in the code, including first names and last names, not even in the form of comments.
- Configure the correct MIME types on your web server for all the different files being used in your web applications.
- Sensitive data, files and any other item of information that do not need to be on the web servers should never be uploaded on the web server.
- Always check whether each of the requests to create/edit/view/delete resources has proper access controls, preventing privilege escalation issues and making sure that all the confidential information remains confidential.
- Make sure that your web application processes user input correctly, and that a generic response is always returned for all the resources that don’t exist/are disallowed in order to confuse attackers.
- Enough validations should be employed by the backend code in order to catch all the exceptions and prevent the leakage of valuable information.
- Configure the web server to suppress any exceptions that may arise and return a generic error page.
- Configure the web server to disallow directory listing and make sure that the web application always shows a default web page.






