How Invicti handles URL rewriting
URL rewriting technology is widely used in modern websites and applications to make URLs more friendly both for humans and for search engines. It also brings its own security challenges, especially for automated testing. This article shows how Invicti’s heuristic URL rewrite technology can automatically identify rewriting rules to accurately scan the entire application.
Your Information will be kept private.
Your Information will be kept private.

Why the modern web loves URL rewriting
Companies take care to pick domain names that are relevant and professional to help users find and remember their websites. However, in the past, not all companies paid the same attention to the rest of the URL, even though what comes after the domain name is also very important. A readable and meaningful URL can improve search rankings and attract more customers. To help with this, URL rewriting was introduced to turn parameter-heavy URLs into something more attractive and SEO-friendly.
For example, this traditional URL is not user-friendly, readable, indexable, or easy to share:
https://example.com/article.php?id=8283&title=all-about-url-rewritingModern web servers apply URL rewrite rules to convert such URLs to a more readable format yet still be able to retrieve the data from a backend database and display the right page to the visitor. The following URL contains the same information but is much cleaner and shorter:
https://example.com/article/8283/all-about-url-rewritingSecurity testing challenges with URL rewriting
While rewriting is great for search engines and users, it can create security challenges for companies that use less advanced automated security scanners. If the scanner fails to identify URL rewriting rules, it can’t fully test a web application. Even if you manually configure the scanner to account for this, your troubles are not over yet.
As a security precaution, most web applications don’t accept rewritten HTTP requests. A scanner configured to apply URL rewrite rules sends special HTTP requests called translated queries. Many applications will deny such requests, so parameters hidden in the URLs won’t be tested – yet the scanner will report that the scan was successful, leaving you with a false sense of security.
If the scanner fails to account for URL rewriting, it may send too many requests and take a very long time to complete a scan. This can happen if the tool doesn’t recognize that some parts of the URL are parameter names and values, not actual directories. It may then try to crawl and attack what it thinks are thousands of unique pages instead of a handful of pages with various parameter values.
For instance, when scanning a web store URL like http://www.example.com/tools/hammer/, the scanner may think that tools and hammer are directories rather than a parameter name and value for a single page like http://www.example.com/store.php?cat=tools&prod=hammer. It will then try to crawl and test every single product page as a separate target, which can lead to extremely long scans or even crash the application.
The pitfalls of configuring URL rewriting manually
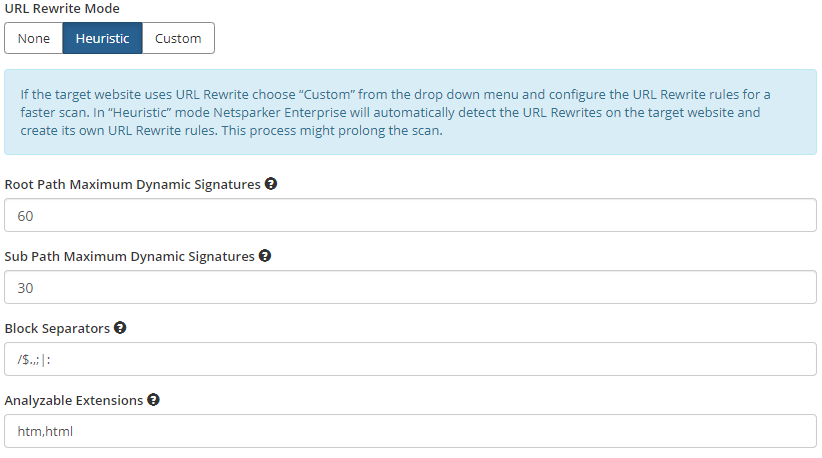
As a modern DAST solution, Invicti provides a rich set of URL rewriting settings. When preparing to launch a new vulnerability scan, you can choose one of three rewriting modes: None, Custom, and Heuristic. In Custom mode, you can manually specify values for the placeholder and regular expression (RegEx) patterns to tell the scanner which parts of the URL are testable parameters.
Doing so, however, requires familiarity with regular expressions. You also need to know the structure of the target website so you can specify the right parameters. But above all, the configuration process can be time-consuming and difficult. To do this manually, you need to be the developer of the web application or at least have a deep understanding of the application (and often direct access to its configuration files). Otherwise, it can be very hard to reliably configure URL rewrite rules for the scanner.
The solution: heuristic URL rewriting
To make it easier to use URL rewriting with the scanner, Invicti provides a heuristic mode as an alternative to manual setup. In heuristic mode, Invicti automatically detects rewrite patterns while crawling the application to identify all possible attack surfaces, including any parameters that accept user or dynamic input. Identified parameters are then used to test for vulnerabilities as usual.
Unlike less advanced web application security scanners, Invicti reliably detects when URL rewriting is enabled. For example, Invicti might crawl 20 URLs in the root path and then analyze 60 sub-path URLs to try and find a matching URL pattern. To identify patterns, Invicti splits URL sub-paths into blocks, so http://www.example.com/blog/first-post/ would be split into /, blog, /, first-post, and / again. While crawling, Invicti will detect that only the first-post block has been changing, so it must be a dynamic parameter. The scanner will then automatically configure its URL rewrite rules to efficiently crawl the website and include this parameter in its attacks.
You can also enable heuristic rewriting in custom mode. This lets you manually configure the URL rewriting rule while also having the scanner check the target site for other rewriting rules. That way, you can take advantage of heuristics even when manually setting up URL rewriting for your site.
Heuristic URL rewriting in practice
To illustrate, we scanned http://aspnet.testsparker.com, one of Invicti’s vulnerable test sites, with and without heuristic URL rewriting. On the New Scan page, we kept all other scan settings identical, including the scan policy and form authentication methods, and changed only the URL rewriting mode.
Setting a baseline with manual configuration
Knowing the structure of the target site, we selected custom URL rewriting for the first scan and provided the required patterns to configure custom mode. Then, we tested the configuration to make sure that the pattern is accurate. The pattern is as follows:
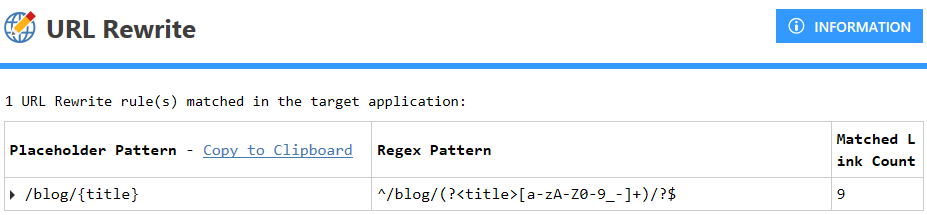
In this test case, Invicti scanned the website and provided the following result:
- Total links: 179
- Total requests: 17506
- Crawled URLs: 180
- Total scan time: 32 minutes 41 seconds
Invicti reported that it crawled 9 posts on page http://aspnet.testsparker.com/Blogs.aspx. Note that while we didn’t set a limit, you can manually optimize scan performance under Scan Policy to limit the number of pages Invicti will crawl in such cases. This can greatly speed up scanning when you have a lot of pages that are identical from a security standpoint and only differ in content.
Scanning with heuristic URL rewriting
In the second test case, we switched to heuristic URL rewriting in the New Scan window but made no other configuration changes. Invicti then automatically identified the URL rewriting pattern on the website during the scan. The pattern is as follows:
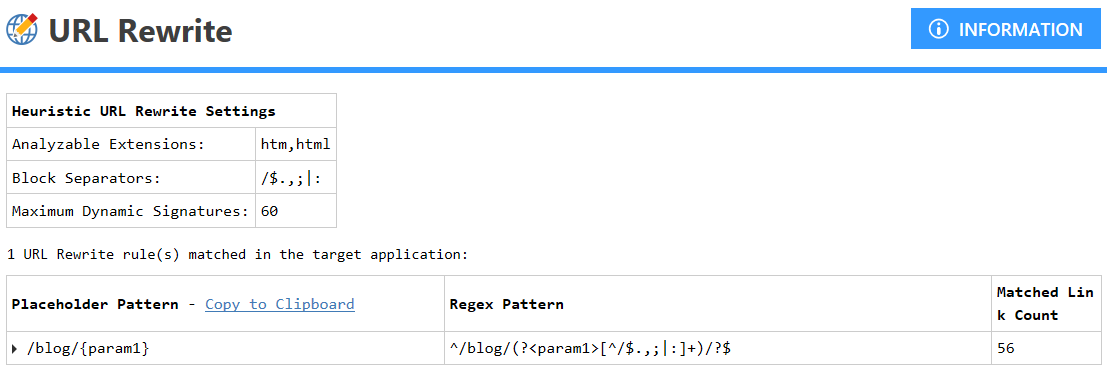
The scan results for this second test case were:
- Total links: 197
- Total requests: 17001
- Crawled URLs: 198
- Total scan time: 37 minutes 42 seconds
The scanner reported that it crawled 28 posts on the blog web page to identify the URL rewriting pattern, with the limit set to 60 web pages. As before, you can separately limit the number of blog pages that Invicti will crawl.
Comparing the results, we can see that Invicti performed in much the same way with one-click fully automatic rewriting detection and with manually preconfigured rules that need expert skills to set up correctly. Crucially, in both tests, Invicti was able to identify all six critical vulnerabilities in the test website.
Better coverage and more accurate results out of the box
URL rewriting has the benefit of making URLs easier to read for humans and easier to index for search engines. However, while hiding internal implementation details such as query parameters can superficially improve security, it actually hinders security testing. If your scanner can’t detect URL rewriting automatically or you don’t get the manual setup just right, the scan may miss some pages or even fail altogether.
As a leading DAST solution, Invicti can confidently detect URL rewriting and scan your websites and applications in their entirety. Heuristic URL rewriting detection brings many benefits:
- Broader scan coverage: Accurate crawling in heuristic mode ensures that every part of the application is tested and you get a realistic picture of your security posture, even when URL rewriting is used.
- More accurate results: The scanner can identify and attack every parameter in your web application to find vulnerabilities, preventing the false sense of security that you may get with incomplete testing. Heuristic mode also eliminates human errors during setup that can lead to incorrect scan results.
- Ease of use: You scan your web applications even if you don’t have the information or resources to manually configure rewriting rules. In any case, because results in heuristic mode are as accurate as with finely-tuned manual parameters, your experts can spend their time on more valuable tasks.
- Effortless scalability: You may have the time and resources to manually configure URL rewriting for one or two websites – but how about a hundred? Or a thousand? Invicti is built for scalability and heuristic rewrite mode is another feature that helps you scan any number of websites with minimum manual intervention.
For more information and FAQs related to URL rewriting in Invicti, see our support page on URL Rewrite Rules and read our white paper on automating URL rewriting in vulnerability scanners.






